
The Ocean Cleanup Challenge
To help The Ocean Cleanup, we’re mobilising hundreds of data scientists & our partners to annotate a massive dataset of polluted ocean photographs. This will allow The Ocean Cleanup to boost the efficiency of their plastic detection model, and accelerate the cleaning of our oceans.
.png?width=890&height=150&name=Untitled-1%20(1).png "Untitled-1 (1)")
Register to participate!
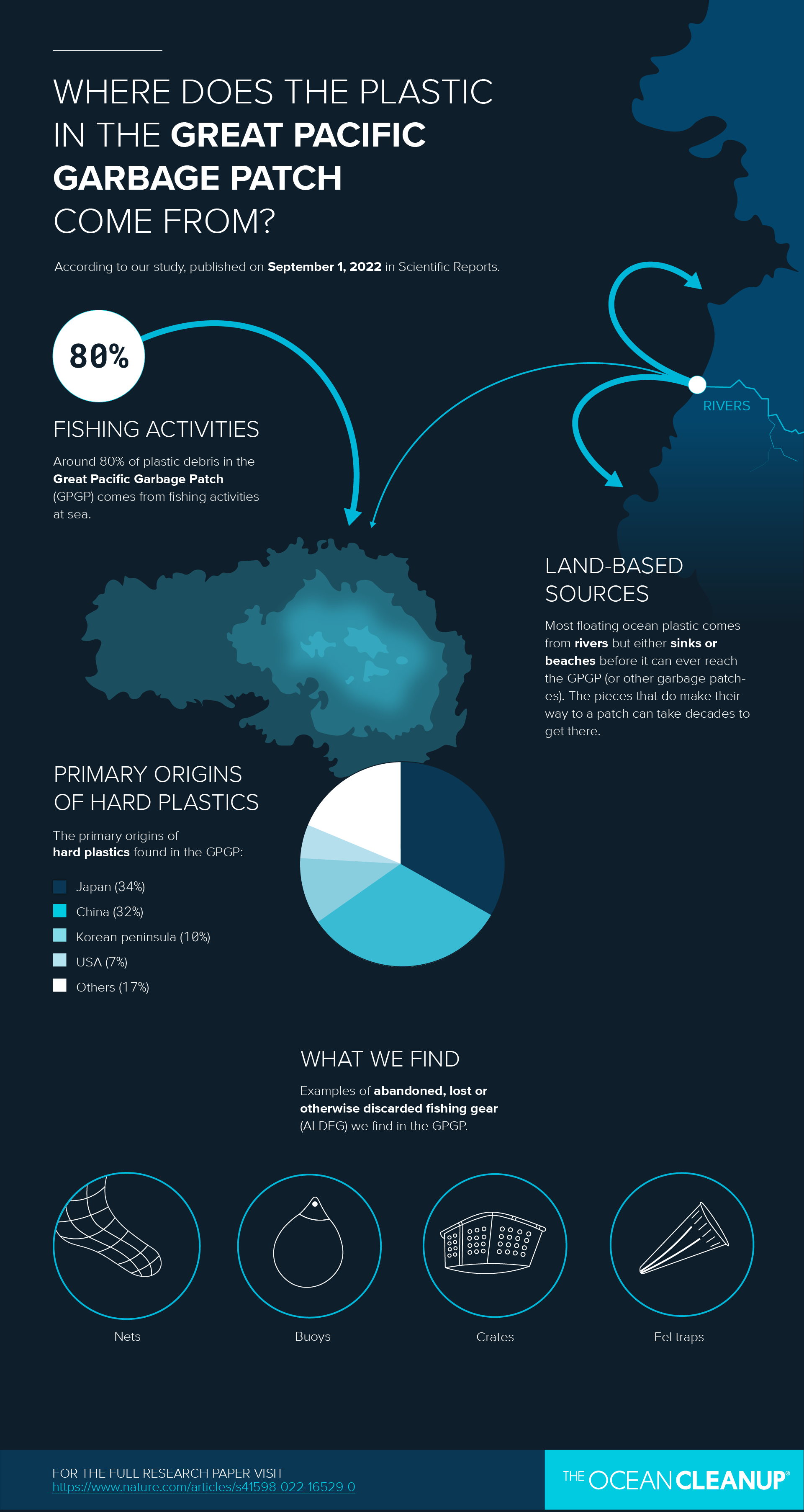
Every year, millions of tons of plastic spill from our rivers to our oceans. A portion of this plastic travels to ocean garbage patches, where it gets caught in circulating currents. These garbage patches are a heavy burden to our oceanic life and if no action is taken, plastic will increasingly impact our ecosystems, health, and economies.
The current datasets were built using conventional methods (trawls) that are very labor-intensive, or less conventional methods (airplane) that are very costly and complex to organize. The team has worked on an AI object detection software, combined with automated time-lapse image series along GPS-tagged transects. This creates a remote sensing approach to detect and map the dynamic behavior of floating ocean plastic more efficiently. Ultimately, this growing dataset will help us determine where to deploy cleanup in an extensive area with an uneven distribution of plastic debris.
To help The Ocean Cleanup in their mission - to remove 90% of floating ocean plastic, we are organising a data-science challenge during which we’re mobilising hundreds of data scientists to annotate a massive dataset of polluted ocean photographs. This will allow The Ocean Cleanup to boost the efficiency of their plastic detection model, and accelerate the cleaning of our oceans.
During the challenge, participants will annotate images from The Ocean Cleanup’s on-board cameras, classifying the detected objects. With a mix of human and model annotation to accelerate the labeling process, your goal will be to label quickly to create the highest quality dataset.
To succeed during the challenge, we put at your disposal:
- Kili Technology's labeling platform to massively pre-annotate, manually annotate as teams & check the quality of annotation
- OVH GPUs to run the pre-annotation and annotation error detection models
- Weights and Biases's platform to track the performance of your pre-annotation models
By participating in this challenge, you’ll be able to:
- discover a passionate community of data-scientists committed to fixing the ecological impacts of our economy
- develop your skillset on a suite of new data-science tools
- participate in the annotation of 100,000+ images of plastic in oceans
Winners of the challenge will be determined on the efficiency & quality of the labeling, and will be rewarded with extensive free vouchers for all solutions and swag packs!
Participants can join as teams or as single contributors. Beginners are welcome. We recommend using Chrome.
Fill the form to join the challenge, and join the challenge's Slack channel.
See you soon!
"We have to spend a lot of time preparing high-quality data before we train the model. Just as a chef would spend a lot of time to source and prepare high-quality ingredients before they cook a meal, a lot of the emphasis of the work in AI should shift to systematic data preparation.“
Andrew Ng, Co-Founder @Google Brain, Founder @Coursera
"Even after 4 years I still haven't "solved" labeling workflows. Labeling, QA, final QA, auto-labeling, error-spotting, diversity massaging, labeling docs & versioning, ppl training, escalations, data cleaning, throughput & quality stats, etc."
Andrej Karpathy, Senior Director @Tesla
“But the real-world experience of those who put them into production shows that (...) it's often the quality of data (...) that makes your AI project succeed or fail.”
Edouard d'Archimbaud, Co-founder & CTO @Kili Technology


